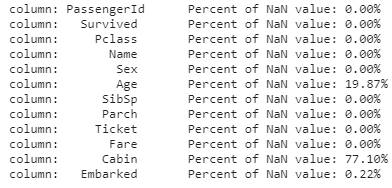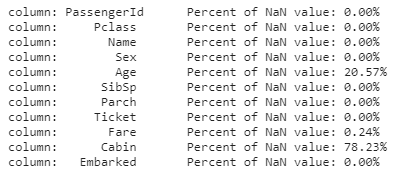def solution(prices):
answer = [0]*len(prices)
for i in range(len(prices)-1):
for j in range(i+1,len(prices)):
if prices[i] <= prices[j]:
answer[i]+=1
else:
answer[i]+=1
break
return answer
from collections import defaultdict
def solution(participant, completion):
answer = ''
hash = defaultdict(int)
for i in participant:
hash[i] += 1
for i in completion:
hash[i] -= 1
for i in participant:
if hash[i] >0:
answer = i
return answer
레벨2 전화번호 목록
def solution(phone_book):
a={}
for i in phone_book:
a[i] = 1
for i in phone_book:
temp=''
for j in i:
temp+=j
if temp in a and temp != i:
return False
return True
레벨2 위장
def solution(clothes):
answer = 1
a={}
for i,j in clothes:
if a.get(j) is None:
a[j] = 2
else:
a[j]+=1
for i in a.values():
answer = i*answer
return answer-1
레벨3 베스트앨범
def solution(genres, plays):
answer = []
a={}
b={}
c={}
for i in range(len(plays)):
if a.get(genres[i]) is None:
a[genres[i]]=plays[i]
b[genres[i]]={}
b[genres[i]][i]=plays[i]
else:
a[genres[i]]+=plays[i]
b[genres[i]][i]=plays[i]
genre_rank = sorted(a.items(),reverse=True,key=lambda a:a[1])
for i,_ in genre_rank:
song_rank=sorted(b[i].items(),reverse=True,key=lambda a:a[1])
print(song_rank)
answer.append(song_rank[0][0])
if len(song_rank) >1:
answer.append(song_rank[1][0])
return answer
# 데이터 처리 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
%matplotlib inline # notebook을 실행한 브라우저에서 바로 그림을 볼 수 있게 해줌.
plt.style.use('seaborn') # 'seaborn' 폰트로 변경
sns.set(font_scale=2.5) # 폰트 크기 설정
# 경고 창 생략
import warnings
warnings.filterwarnings('ignore')
seaborn은 matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지입니다.
데이터를 불러올 때 pandas를 사용합니다. pandas는 데이터를 처리하는 강력한 도구입니다. csv 파일의 가장 위에 있는 인덱스를 columns로 지정합니다.
head
df_train.head(5)
head 함수는 pandas로 불러온 데이터를 위에서부터 숫자만큼 순서대로 불러옵니다.
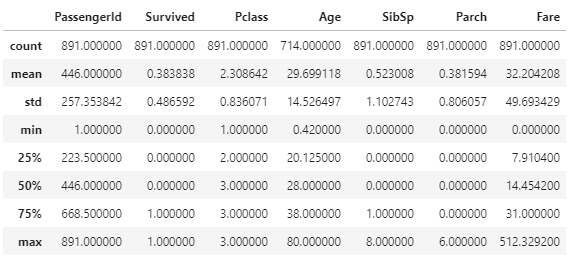
describe
df_train.describe()
describe 함수는 데이터 통계 분석 도구입니다. 개수, 평균, 표준편차, 최소값 등을 표로 멋지게 표현해줍니다.
3. 데이터 대략적 분석하기
①결측값 파악하기
df_train
for col in df_train.columns:
print('{:>10}\t Percentage of NaN value: {:.2f}'.format(col, 100*(df_train[col].isnull().sum() / len(df_train[col].shape[0]))))
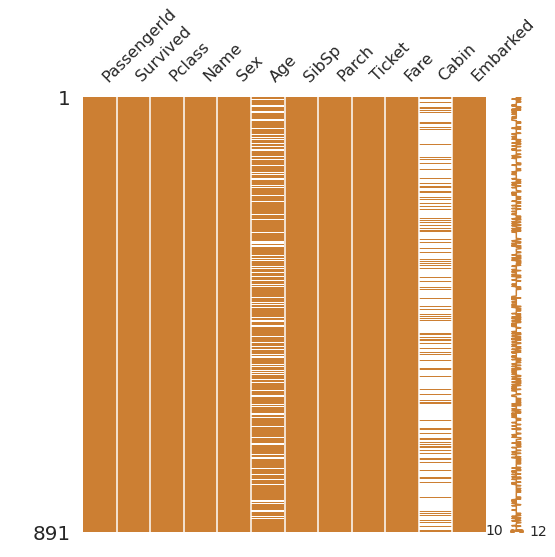
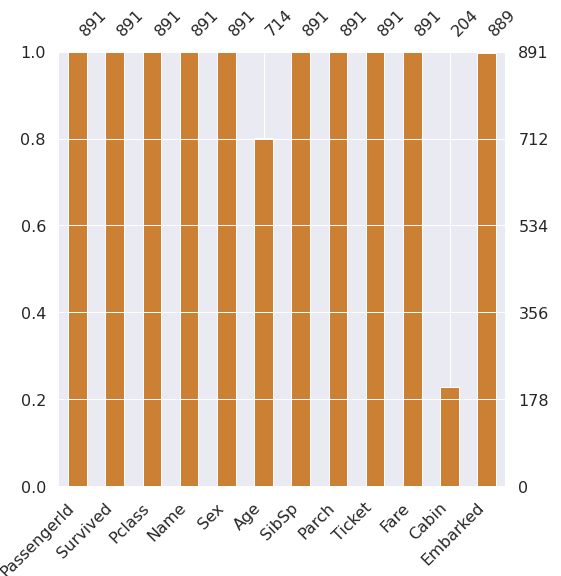
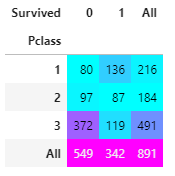
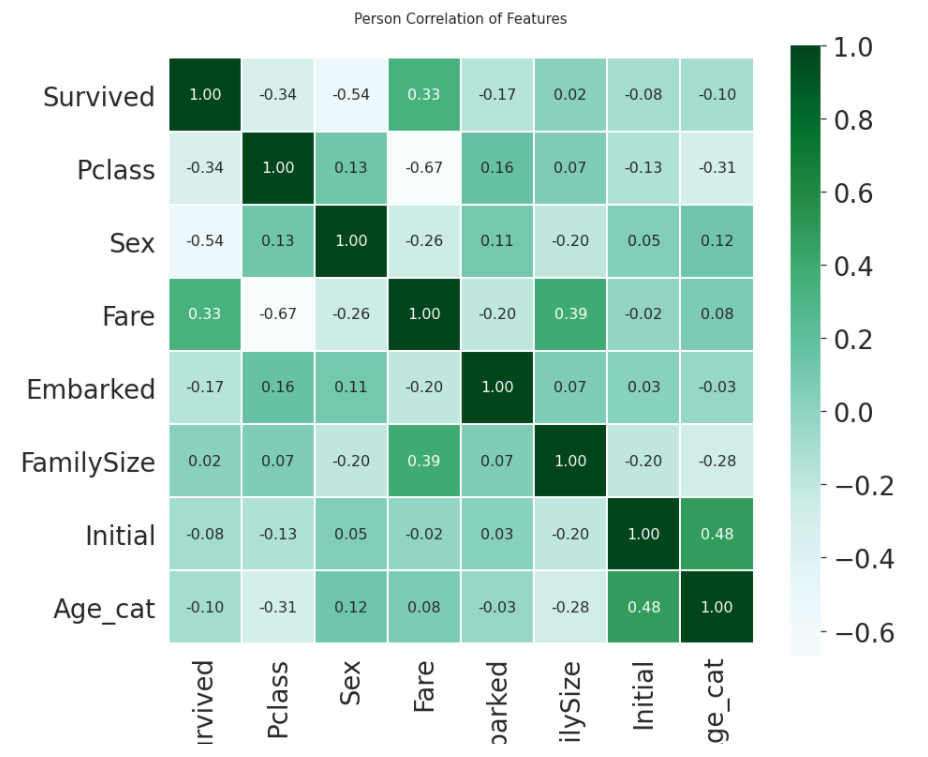
df_train에는 12개의 columns가 들어있습니다. 이 중 Age, Cabin, Embarked 3가지엔 결측값이 존재하므로 이를 다른 값으로 채워주거나, feature를 사용하지 않는 방법 중 하나를 택해야 합니다. 이 때, Cabin은 결측값의 비율이 77프로에 육박하므로 사용하지 않는 편이 낫겠습니다.
df_test
for col in df_test.columns:
print('{:>10}\t Percentage of NaN value: {.2f}'.format(col, df_test[col].isnull().sum() / len(df_test[col].shape[0])))
df_test는 Age, Fare, Cabin 3가지에 관하여 결측값이 존재하고 df_train과 달리 Fare에 결측값이 존재합니다. 마찬가지로 Cabin의 결측값 비율은 높으므로 사용하지 않습니다.
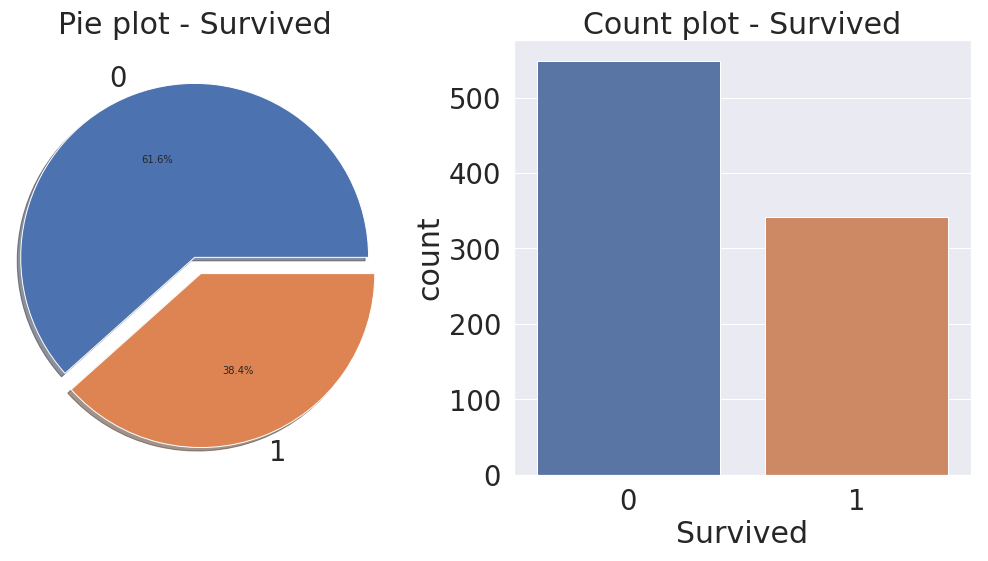
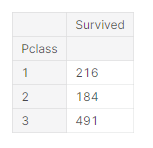
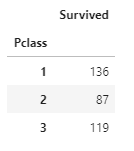
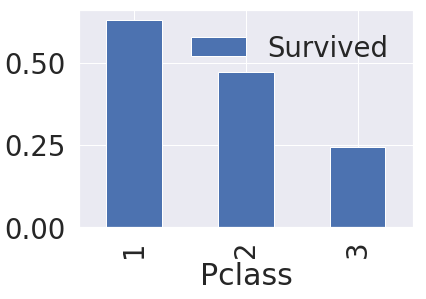
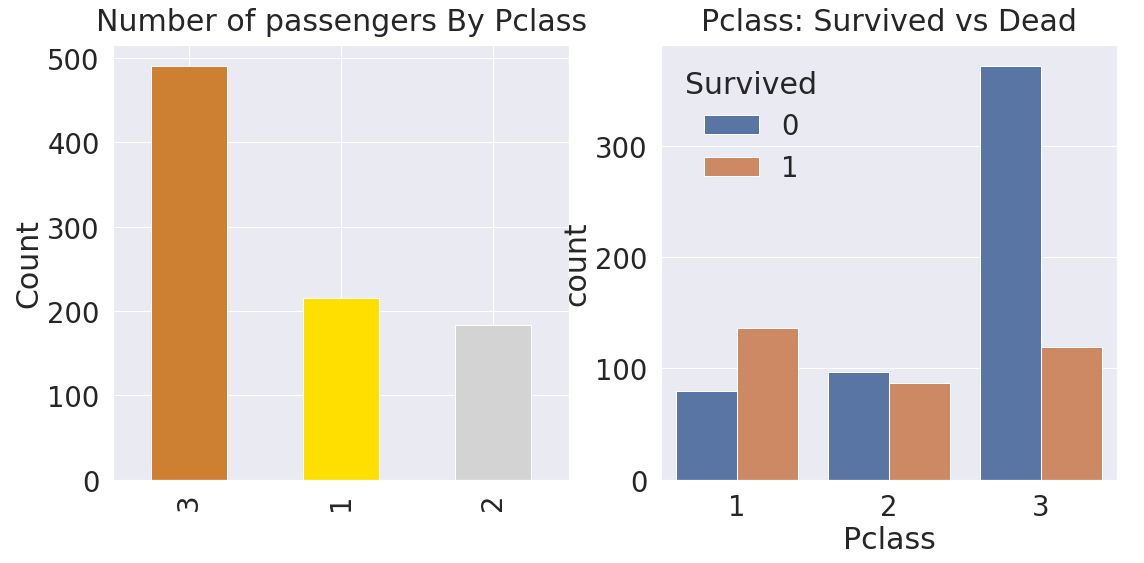
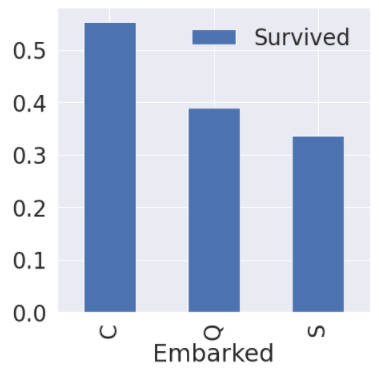
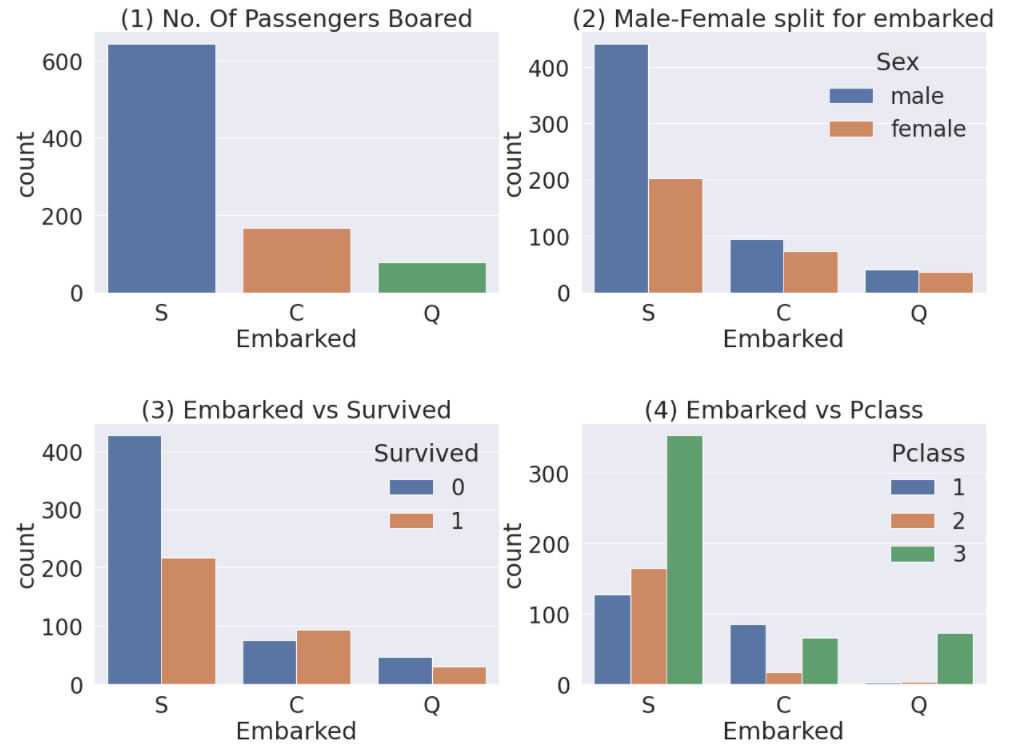
생존률을 구한 다음 생존률이 높은 순(ascending=False)대로 히스토그램을 그렸습니다. 티켓 등급이 높을수록 생존률이 높습니다. 돈이 많은 사람이 생존할 확률이 높다는 것을 알 수 있습니다. 역시.. 재력이..
y_position = 1.02
f, ax = plt.subplots(1,2,figsize=(18,8))
df_train['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'],ax=ax[0]])
ax[0].set_title('Number of passengers By Pclass', y = y_position)
ax[0].set_title('Count')
sns.countplot('Pclass', hue='Survived',data=df_train, ax=ax[1])
ax[1].set_title('Pclass: Survived vs Dead', y = y_position)
plt.show()
matplotlib.pyplot의 subplots 함수는 그래프를 그릴 개수와 그래프의 크기를 설정합니다. 첫번째 ax[0] 위치에는 티켓 등급별로 인원수를 히스토그램으로 나타내고, 두번째 ax[1] 위치에는 seaborn의 countplot 함수를 사용하여 티켓 등급별로 사망자와 생존자를 나타내도록 했습니다. 그래프의 set_title 함수를 사용하여 각 그래프의 제목을 나타내줍니다.
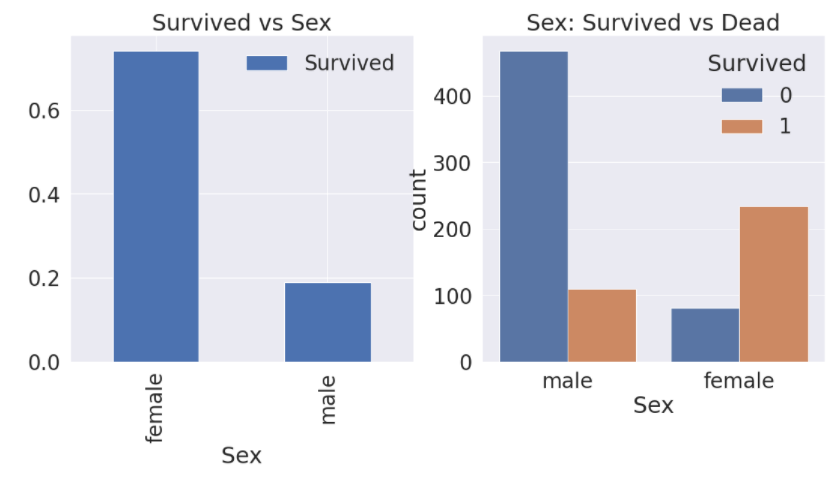
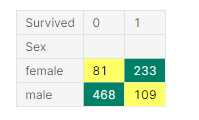
② Sex
f, ax = plt.subplots(1,2,figsize=(18,8))
df_train[['Sex','Survived']].groupby(['Sex'],as_index=True).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex', hue='Survived', data=df_train,ax=ax[1])
ax[1].set_title('Sex: Survived vs Dead')
plt.show()
factorplot은 x, y 축에 두가지의 값을 받고, hue에 있는 데이터를 분류하여 그래프로 표현합니다.
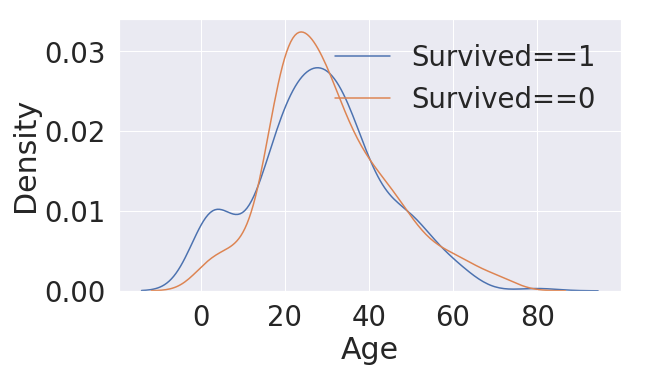
③ Age
연령 분석
print('제일 나이 많은 탑승객: {:.1f}'.format(df_train['Age'].max())
print('제일 나이 어린 탑승객: {:.1f}'.format(df_train['Age'].min())
print('탑승객 평균 나이 : {.1f}'.format(df_train['Age'].mean())
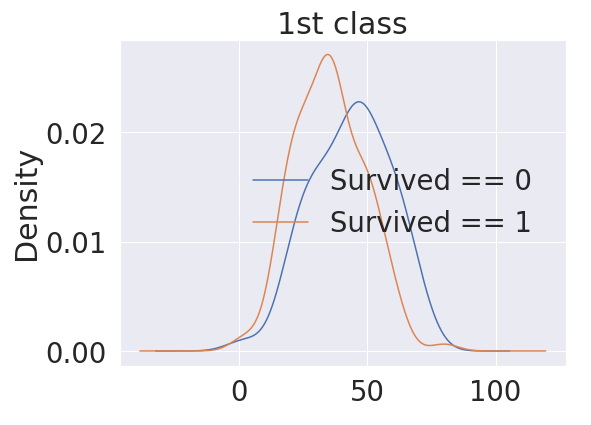
seaborn의 kdeplot은 커널밀도함수로 데이터에 맞게 그래프를 fitting 해주는 함수입니다. Age가 0 이하로는 실제 데이터가 없지만 그래프를 fitting 한 결과로 저렇게 그려집니다. 히스토그램으로 그릴 경우 비교할 대상이 겹치면 보이지 않는 현상이 나타나지만, kdeplot은 여러개를 비교할 수 있습니다.
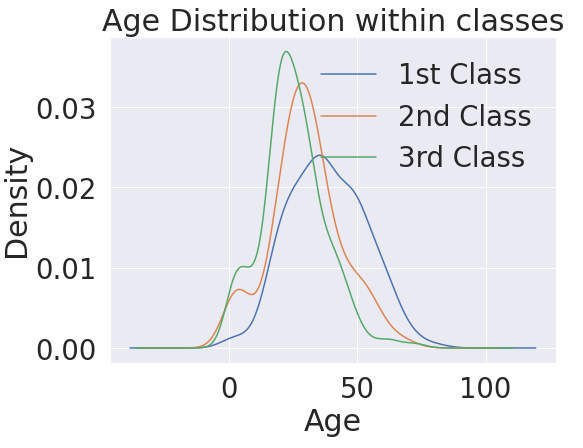
plt.subplots(1,1,figsize=(8,6))
df_train[df_train['Pclass']==1]['Age'].plot(kind='kde')
df_train[df_train['Pclass']==2]['Age'].plot(kind='kde')
df_train[df_train['Pclass']==3]['Age'].plot(kind='kde')
plt.legend(['1st Class','2nd Class','3rd Class'])
plt.title('Age Distribution within classes')
plt.xlabel('Age')
plt.show()
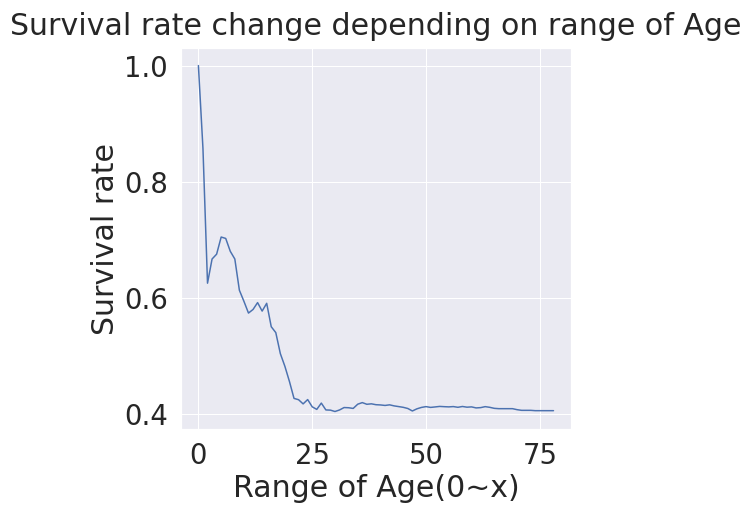
plt.figure(figsize=(8,6))
aging_survived_ratio=[]
for i in range(80):
aging_survived_ratio.append(df_train[(df_train['Age'] <= i)]['Survived'].sum() / len(df_train[df_train['Age']<=i]['Survived'])
plt.plot(aging_survived_ratio)
plt.title('Survival ratio change depending on range of Age')
plt.xlabel('Age 0~x')
plt.show()
해당 나이까지의 생존률을 나타낸 그래프를 보면 나이가 영유아는 생존률이 높은 것을 알 수 있습니다. 나이가 들수록 생존률이 줄어듭니다.
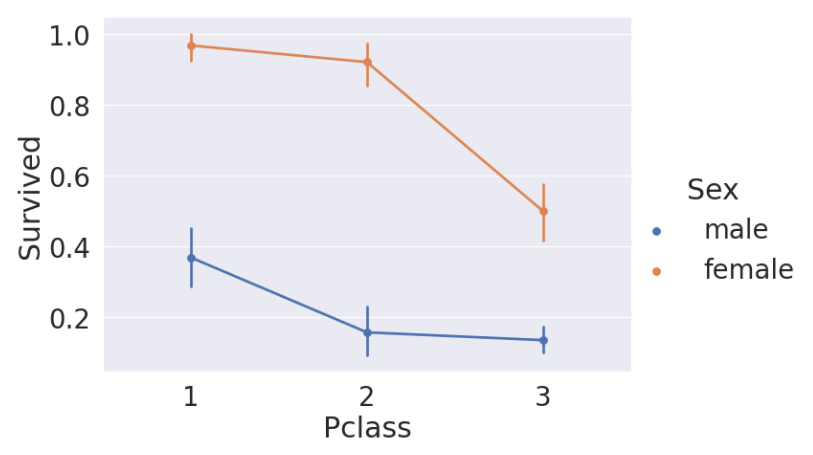
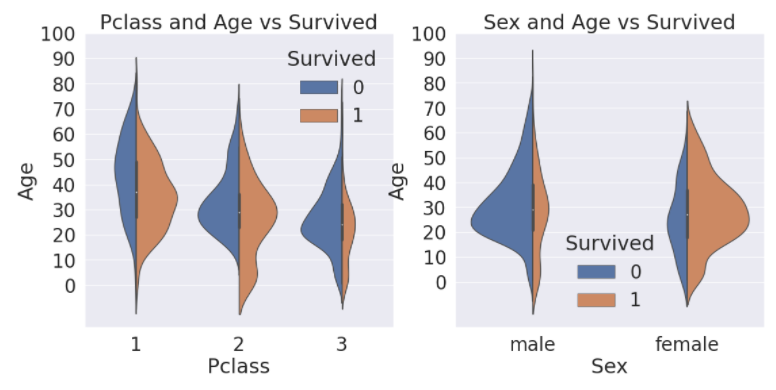
Pclass, Sex, Age
f, ax = plt.subplots(1,2,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived', data=df_train, scale='count', split=True, ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex', 'Age', hue='Survived',data=df_train,scale='count',split=True, ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
violinplot은 그래프의 형태가 바이올린을 닮았다고 해서 붙여진 이름입니다. violinplot을 통해 티켓등급이 높고 나이가 어리며, 여성이라면 살아남을 확률이 더 높은 것을 한 눈에 확인할 수 있습니다.
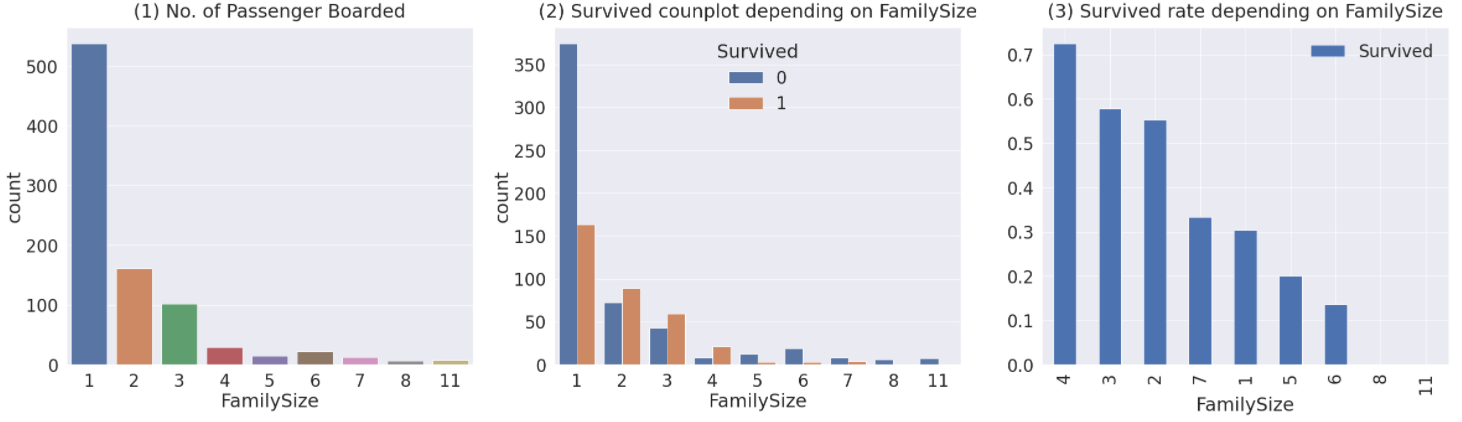
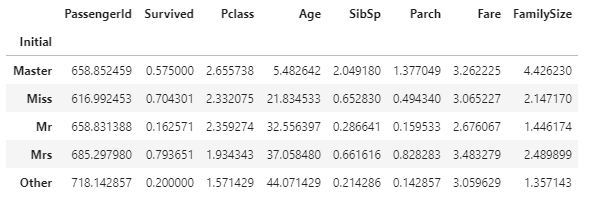
가족 인원수가 생존률에 미치는 영향을 나타낸 그래프입니다. 이 때, set_title 함수의 y는 title의 위치를 지정해줍니다. default는 1입니다.
⑥ Fare
fig, ax = plt.subplots(1,1,figsize=(8,8))
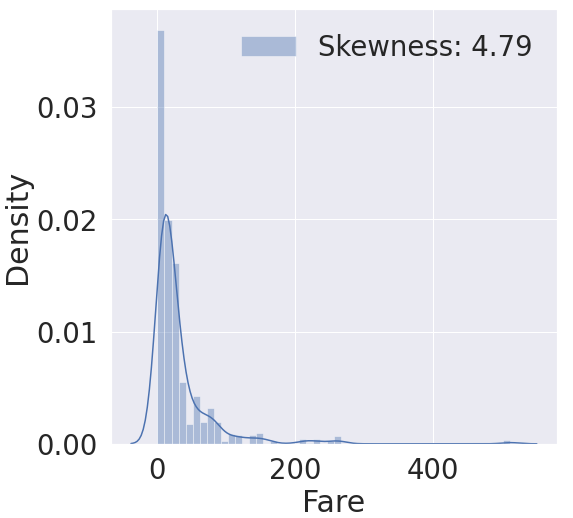
g = sns.distplot(df_train['Fare'], color='b', label='skewness: {:.2f}'.format(df_train['Fare'].skew()),ax=ax)
g = g.legend(loc='best')
fare 은 데이터가 한쪽으로 치우쳐진 모습을 볼 수 있습니다. 이를 객관적으로 나타내는 지표가 skewness, 왜도입니다. 왜도는 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표입니다. 왜도 값이 클수록 데이터가 치우쳐 있는 것을 확인할 수 있습니다. 이를 고르게 퍼뜨리기 위해서 log 함수를 취합니다.
df_train['Fare'] = df_train['Fare'].map(lambda i: np.log(i) if i>0 else 0)
df_test['Fare'] = df_test['Fare'].map(lambda i: np.log(i) if i>0 else 0)
fig, ax = plt.subplots(1,1,figsize=(8,8))
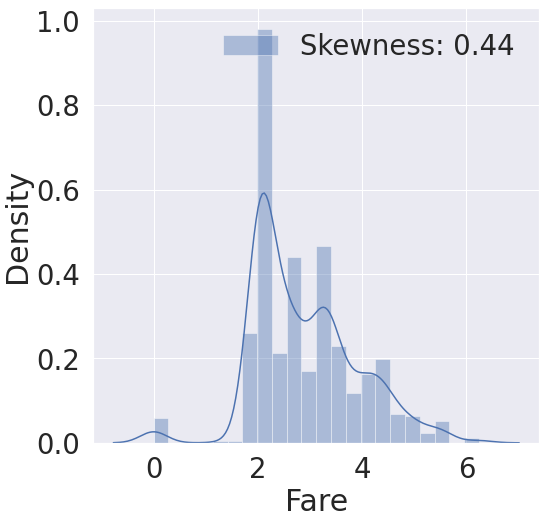
g = sns.distplot(df_train['Fare'], color ='b', label='Skewness: {:.2f}'.format(df_train['Fare'].skew()),ax=ax)
g = g.legend(loc='best')
아까와 다르게 skewness 가 0에 가까워졌고, 데이터가 조금 더 고르게 퍼져 있는 모습을 볼 수 있습니다.
⑦ Ticket
티켓 이름은 데이터로 처리하기 까다롭고, 티켓 이름 간에 그렇게 큰 연관성이 보이지 않기 때문에 모델이 학습할 데이터에서 제외하도록 하겠습니다.
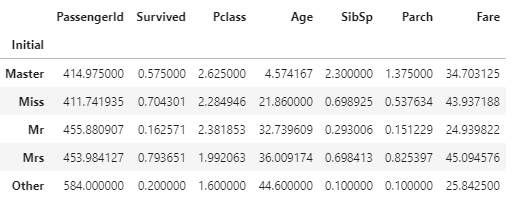
정규 표현식을 사용하여 이름에서 영어 호칭만을 추출해냅니다. [A-Za-z]는 모든 알파벳을 의미하고, '+'는 앞에 있는 것이 1번 이상 반복되는 것을 의미합니다. 따라서, '.'으로 끝나는 알파벳 단어를 추출해내면 우리가 원하는 영어 호칭만을 추출할 수 있습니다. 이를 새로운 column인 Initial을 만들어 저장합니다.
영어 호칭과 도착할 항구는 숫자 값으로 맵핑할 때 연속된 수의 개념보다는 분류의 개념이 더 크기 때문에 원핫 인코딩 기법을 사용하여 데이터를 표현해줍니다. 그리고 필요없는 데이터 column은 삭제하여줍니다. 이로써 데이터 전처리가 완료되었습니다. 간단히 모델을 설계하여 생존자를 예측해보도록 합니다.
7. 모델 설계하기
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split
X_train = df_train.drop(['Survived'],axis=1)
target_label = df_train['Survived'].values
X_test = df_test.values
x_tr, x_vld, y_tr, y_vld = train_test_split(X_train, target_label, test_size=0.3, random_state=2018)
model = RandomForestClassifier()
model.fit(X_tr, y_tr)